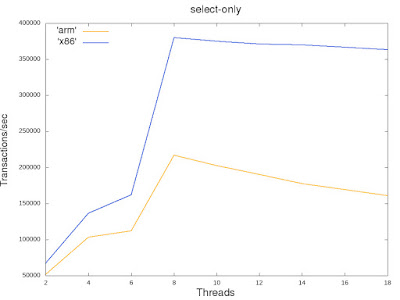
Need for external compression methods in PostgreSQL
Every modern database system has some way to compress its data at some level. The obvious reason for this feature is to reduce the size of it's database, especially in today's world where the data is growing exponentially. The less obvious reason is to improve query performance; the idea is: smaller data size means less data pages to scan, which means lesser disk i/o and faster data access. So, in any case, data de-compression should be fast enough so as not to hamper the query performance, if not improve it. Compression is offered at different levels : page compression, row compression, column compression, etc. Columnar databases have the advantage of a very high compression ratio of its column because of presence of a repetetive pattern of contiguous data in a column. Another case is when, in a row oriented database, the column values are so large that it makes sense to compress individual values of the column. Such values can even be kept separately if they do not fit in a ...