PostgreSQL on ARM
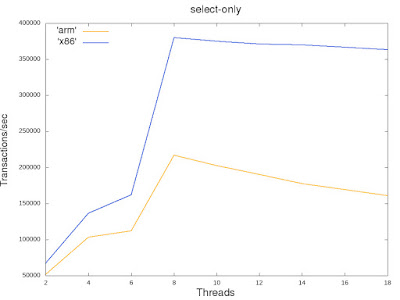
In my last blog , I wrote that applications that have been running on x86 might need to undergo some adaptation if they are to be run on a different architecture such as ARM. Let's see what it means exactly. Recently I have been playing around with PostgreSQL RDBMS using an ARM64 machine. A few months back, I even didn't know whether it can be compiled on ARM, being oblivious of the fact that we already have a regular build farm member for ARM64 for quite a while . And now even the PostgreSQL apt repository has started making PostgreSQL packages available for ARM64 architecture. But the real confidence on the reliability of PostgreSQL-on-ARM came after I tested it with different kinds of scenarios. I started with read-only pgbench tests and compared the results on the x86_64 and the ARM64 VMs available to me. The aim was not to compare any specific CPU implementation. The idea was to find out scenarios where PostgreSQL on ARM does not perform in one scenario as good as...