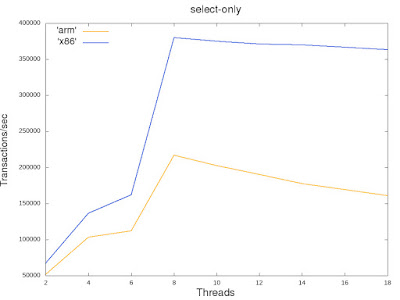
A quick sanity testing of pgpool-II on ARM64
pgpool-II is a well-known tool to pool PostgreSQL connections and load-balance work loads. In this blog, we will verify whether pgpool works well on ARM64 architecture. ARM64 packages On Ubuntu, pgpool2 ARM64 debian package is made available by the Debian PostgreSQL Maintainers : $ dpkg -s pgpool2 Maintainer: Debian PostgreSQL Maintainers <team+postgresql@tracker.debian.org> Architecture: arm64 Version: 4.1.4-3.pgdg18.04+2 Replaces: pgpool Depends: libpgpool0 (= 4.1.4-3.pgdg18.04+2), lsb-base (>= 3.0-3), postgresql-common (>= 26), ucf, libc6 (>= 2.17), libmemcached11, libpam0g (>= 0.99.7.1), libpq5, libssl1.1 (>= 1.1.0) On CentOS, the ARM64 yum packages are not available. But you can always download the source from the repository or using git and then install from the source. Installation from source pgpool build requires installed PostgreSQL on the same machine. The build uses 'pg_config' command to locate the required PostgreSQL header files, library...