A quick sanity testing of pgpool-II on ARM64
pgpool-II is a well-known tool to pool PostgreSQL connections and load-balance work loads. In this blog, we will verify whether pgpool works well on ARM64 architecture.
ARM64 packages
On Ubuntu, pgpool2 ARM64 debian package is made available by the Debian PostgreSQL Maintainers :
$ dpkg -s pgpool2
Maintainer: Debian PostgreSQL Maintainers <team+postgresql@tracker.debian.org>
Architecture: arm64
Version: 4.1.4-3.pgdg18.04+2
Replaces: pgpool
Depends: libpgpool0 (= 4.1.4-3.pgdg18.04+2), lsb-base (>= 3.0-3), postgresql-common (>= 26), ucf, libc6 (>= 2.17), libmemcached11, libpam0g (>= 0.99.7.1), libpq5, libssl1.1 (>= 1.1.0)
On CentOS, the ARM64 yum packages are not available. But you can always download the source from the repository or using git and then install from the source.
Installation from source
pgpool build requires installed PostgreSQL on the same machine. The build uses 'pg_config' command to locate the required PostgreSQL header files, library files, and executables. So ensure that your PATH environment variable has the PostgreSQL bin directory so that './configure' pickups up the right pg_config :
export PATH=<PostgreSQL_rootdir>/bin:$PATH
$ ./configure --prefix=<pgpool_installation_location>
pgpool will be installed at the location specified by --prefix.
Alternatively, you can explicitly specify the required PostgreSQL directories :
$ PGDIR=<PostgreSQL_rootdir>
$ ./configure --prefix=<pgpool_installation_location> --with-pgsql-includedir=$PGDIR/include --with-pgsql-libdir=$PGDIR/lib -with-pgsql-bindir=$PGDIR/bin
If you downloaded the source from the git repository, you need to set the branch to the latest stable one :
$ git branch --track V4_2_STABLE remotes/origin/V4_2_STABLE
$ git checkout V4_2_STABLE
$ git branch
* V4_2_STABLE
master
Now install pgpool2:
$ make
$ make install
Create a pcp.conf file out of the supplied sample file:
export PGPOOLDIR=<pgpool_top_dir>
cd $PGPOOLDIR
cp ./etc/pcp.conf.sample ./etc/pcp.conf
pgpool supports different clustering modes. We will use the most popular and recommended clustering mode : streaming replication mode. Use the relevant sample configuration file to set up our configuration:
cp etc/pgpool.conf.sample-stream etc/pgpool.conf
This file always has the backend_clustering_mode set to 'streaming_replication'. We do not have to change it.
We need to set up PostgreSQL streaming replication before starting up pgpool. The following assumes that streaming replication is already setup, with the data directories for primary and standby server located at /home/amit/replication/pg/data/primary and /home/amit/replication/pg/data/standby, respectively. And they are running on port 26501 and 26502, respectively.
Configuration file
In the etc/pgpool.config file, I did these modifications :
pid_file_name = 'pgpool.pid'
listen_addresses = '*'
sr_check_user = 'amit'
backend_hostname0 = 'localhost'
backend_port0 = 26501
backend_weight0 = 1
backend_data_directory0 = '/home/amit/replication/pg/data'
backend_hostname1 = 'localhost'
backend_port1 = 26502
backend_weight1 = 1
backend_data_directory1 = '/home/amit/replication/slave/data'
logdir = '/home/amit/ins/pgpool/log'
- 'pid_file_name' specifies the full path to a file to store the pgpool2 process id. The default value is /var/run/pgpool/pgpool.pid. This directory path was not accessible, so I had to change it to relative path name, i.e. relative to the location of pgpool.conf file.
- 'sr_check_user' specifies the PostgreSQL user name to perform streaming replication check. The default value 'nobody' didn't work for obvious reasons.
- 'backend_hostname' and 'backend_port' specify the hostname and port on which primary and standby are running. backend_data_directory points to their data directory. In our case, there are only two instances, so we used suffixes 0 and 1. We can add more instances with incrementing number suffixes.
- I had configured streaming replication with both primary and standby on the same machine where pgpool is installed. So used 'localhost' for backend_hostname for both of them.
- backend_weight0 and backend_weight1 together specify the ratio in which the load is balanced among the PostgreSQL instances. E.g. 1:1 means equal balancing, 1:3 means standby should bear around 3/4th of the total load; etc.
- Setting 'logdir' to an existing directory is important, because the node status is stored in that path. I observed that not setting this parameter results in only one node getting used, which means load balancing does not happen.
Starting up pgpool
Now let's bring the pgpool binary location into the PATH before we bring up pgpool :
export PGPOOLDIR=<pgpool_top_dir>
export LD_LIBRARY_PATH=$PGPOOLDIR/lib:$LD_LIBRARY_PATH
export PATH=$PGPOOLDIR/bin:$PATH
We have both pcp.conf and pgpool.conf files on default paths ($PGPOOLDIR/etc), with default names, so we don't have to explicitly specify them using -f or -F option of pgpool command:
$ pgpool -n
2021-07-08 01:44:12: main pid 14435: LOG: health_check_stats_shared_memory_size: requested size: 12288
2021-07-08 01:44:12: main pid 14435: LOG: memory cache initialized
2021-07-08 01:44:12: main pid 14435: DETAIL: memcache blocks :64
2021-07-08 01:44:12: main pid 14435: LOG: allocating (136571704) bytes of shared memory segment
2021-07-08 01:44:12: main pid 14435: LOG: allocating shared memory segment of size: 136571704
2021-07-08 01:44:12: main pid 14435: LOG: health_check_stats_shared_memory_size: requested size: 12288
2021-07-08 01:44:12: main pid 14435: LOG: health_check_stats_shared_memory_size: requested size: 12288
2021-07-08 01:44:12: main pid 14435: LOG: memory cache initialized
2021-07-08 01:44:12: main pid 14435: DETAIL: memcache blocks :64
2021-07-08 01:44:12: main pid 14435: LOG: pool_discard_oid_maps: discarded memqcache oid maps
2021-07-08 01:44:12: main pid 14435: LOG: Setting up socket for 0.0.0.0:9999
2021-07-08 01:44:12: main pid 14435: LOG: Setting up socket for :::9999
2021-07-08 01:44:12: main pid 14435: LOG: find_primary_node_repeatedly: waiting for finding a primary node
2021-07-08 01:44:12: main pid 14435: LOG: find_primary_node: primary node is 0
2021-07-08 01:44:12: main pid 14435: LOG: find_primary_node: standby node is 1
2021-07-08 01:44:12: health_check pid 14474: LOG: process started
2021-07-08 01:44:12: health_check pid 14475: LOG: process started
2021-07-08 01:44:12: sr_check_worker pid 14473: LOG: process started
2021-07-08 01:44:12: pcp_main pid 14472: LOG: PCP process: 14472 started
2021-07-08 01:44:12: main pid 14435: LOG: pgpool-II successfully started. version 4.2.3 (chichiriboshi)
2021-07-08 01:44:12: main pid 14435: LOG: node status[0]: 1
2021-07-08 01:44:12: main pid 14435: LOG: node status[1]: 2
Ok, so pgpool is now up. It is listening on port 9999, which is the value that came from pgconf.conf.sample. Now any PostgreSQL client can connect with "-p 9999".
I can see 32 pgpool processes waiting for connection request :
amit 9884 9881 0 00:02 pts/3 00:00:00 pgpool: wait for connection request
amit 9885 9881 0 00:02 pts/3 00:00:00 pgpool: wait for connection request
amit 9886 9881 0 00:02 pts/3 00:00:00 pgpool: wait for connection request
amit 9887 9881 0 00:02 pts/3 00:00:00 pgpool: wait for connection request
............
............
These are pre-forked pgpool2 processes. pgpool parameter 'num_init_children' decides how many such processes should be spawned, as part of the connection pool.
Now let's see if pgpool identifies the primary and standby :
$ psql -p 9999 -c "show pool_nodes"
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-----------+-------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | localhost | 26501 | up | 0.500000 | primary | 0 | true | 0 | | | 2021-07-08 01:41:34
1 | localhost | 26502 | up | 0.500000 | standby | 0 | false | 0 | | | 2021-07-08 01:41:34
(2 rows)
Load Balancing
Now let's run pgbench with a read-only workload, using pgpool:
pg:s2:pgpool$ pgbench -c 30 -j 30 -p 9999 -T 30 -n -S
pgbench (PostgreSQL) 14.0
transaction type: <builtin: select only>
scaling factor: 30
query mode: simple
number of clients: 30
number of threads: 30
duration: 30 s
number of transactions actually processed: 834074
latency average = 1.078 ms
initial connection time = 20.744 ms
tps = 27817.538209 (without initial connection time)
$ psql -p 9999 -c "show pool_nodes"
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-----------+-------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | localhost | 26501 | up | 0.500000 | primary | 362792 | true | 0 | | | 2021-07-08 01:52:23
1 | localhost | 26502 | up | 0.500000 | standby | 471282 | false | 0 | | | 2021-07-08 01:52:23
(2 rows)
We can see that the select_cnt column shows roughly equal number of select statements, which is expected, given 1:1 load_balance weight. So let's change the ratio to 1:5 :
backend_weight0 = 1
backend_weight1 = 5
pg:s2:pgpool$ psql -p 9999 -c "show pool_nodes"
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-----------+-------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | localhost | 26501 | up | 0.166667 | primary | 165955 | false | 0 | | | 2021-07-08 02:04:35
1 | localhost | 26502 | up | 0.833333 | standby | 665867 | true | 0 | | | 2021-07-08 02:04:35
The select_cnt for standby is indeed much more than for primary.
Read-write work-load
Let's run the pgbench tpcb-like work load with pgpool :
pg:s2:pgpool$ pgbench -c 30 -j 30 -p 9999 -T 40 -n
pgbench (PostgreSQL) 14.0
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 30
query mode: simple
number of clients: 30
number of threads: 30
duration: 40 s
number of transactions actually processed: 80917
latency average = 14.866 ms
initial connection time = 24.412 ms
tps = 2018.063384 (without initial connection time)
$ psql -p 9999 -c "show pool_nodes"
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change
---------+-----------+-------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+---------------------
0 | localhost | 26501 | up | 0.500000 | primary | 80883 | false | 0 | | | 2021-07-08 02:36:43
1 | localhost | 26502 | up | 0.500000 | standby | 0 | true | 0 | | | 2021-07-08 02:36:43
You can see that standby did not get any select queries, even when there is one select statement in the tpcb-like script. The reason is: the select statements are preceded by DML statements in the same transaction. In such case, pgpool decides not to load-balance the select statements within the transaction, so that the select statements can see the updates made by the ongoing transaction.
Performance impact of load balancing
To observe any improvement in performance numbers due to load balancing, I am going to run some long running queries so as to reduce the noise of connection pooling and pgpool statement parsing. With my setup of an 8 CPU VM, pgbench gives slower results when pgpool is used, due to the connection noise.
So my pgbench custom script my.sql looks like this :
select avg(aid), avg(bid) , avg(abalance) from pgbench_accounts;
select avg(aid), avg(bid) , avg(abalance) from pgbench_accounts;
select avg(aid), avg(bid) , avg(abalance) from pgbench_accounts;
select avg(aid), avg(bid) , avg(abalance) from pgbench_accounts;
...........
...........
To simulate primary and secondary as though they are on different machines, let's run each of them on a separate set of 4 CPUs:
numactl --physcpubind=0-3 pg_ctl -D $MASTERDATA -l $MASTERDATA/postgres.log -w start
numactl --physcpubind=4-7 pg_ctl -D $STANDBYDATA -l $STANDBYDATA/postgres.log -w start
First, let's run pgbench directly with the primary server :
$ pgbench -c 8 -j 8 -p 26501 -T 60 -n -f /tmp/my.sql
pgbench (PostgreSQL) 14.0
transaction type: /tmp/my.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
duration: 60 s
number of transactions actually processed: 18
latency average = 34973.239 ms
initial connection time = 4.879 ms
tps = 0.228746 (without initial connection time)
Now, let's run pgbench with pgpool :
$ pgbench -c 8 -j 8 -p 9999 -T 60 -n -f /tmp/my.sql
pgbench (PostgreSQL) 14.0
transaction type: /tmp/my.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
duration: 60 s
number of transactions actually processed: 29
latency average = 21008.485 ms
initial connection time = 7.001 ms
tps = 0.380799 (without initial connection time)
You can see that the transactions processed with pgpool were 29, whereas when bypassed pgpool, only 18 transactions were processed. This difference is because pgpool distributes the select queries over to the primary and standby.
Conclusion
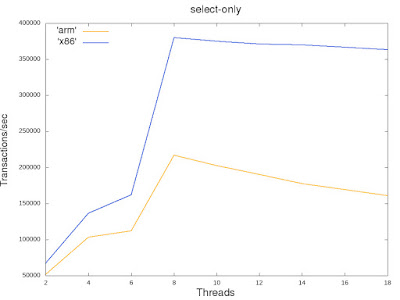
Debian packages are available for pgpool on ARM64. For platforms where Arm64 pgpool package is not available, installation using source goes smoothly.
We have seen that pgpool load balancing works sanely on ARM64.
There are so many other parameters and features that could be tested, but it would take another blog to cover them. In a future blog, I hope to verify the automatic failover of pgpool.
Comments
Post a Comment